15 KiB
| parents | aliases | tags | date | ||||
|---|---|---|---|---|---|---|---|
|
|
2022-10-14 |
Организатор:: ../../meta/organizations/JUG Ru Group Конференция:: ../conference/Конференция. Jpont 2022 Автор:: ../../meta/people/Сальников Андрей Ссылка:: Андрей Сальников — Индексы в PostgreSQL. Как понять, что создавать - YouTube
О чем доклад: Любой разработчик знает, что индексы — это мощный инструмент, который может улучшить работу запросов в базе данных и, как следствие, сократить отклик приложения или сервиса на внешние запросы. Но опыт Андрея, как ДБА, показывает, что у разработчиков нет понимания, какой, когда и из каких соображений можно создавать индекс. Спикер приведет простые и понятные примеры, которые вы сможете легко повторить на своих реальных базах данных.
В докладе в основном говорится об ../../dev/database/Online Transaction Processing нагрузке и объем баз данных от 20 Гб до 10 Тб.
Тезисы
Конспект
Многие разработчики не проводят исследовательскую работу перед созданием индексов и создают их как считают правильно, и не всегда это мнение совпадает с реальностью.
Первым делом стоит ознакомиться с документаций: PostgreSQL: Documentation: 16: CREATE INDEX
Прежде чем создавать индексы, нужно понять что такое индексы. Фактически это легализованные косты для ../../dev/database/Оптимизация SQL запросов. В PostgreSQL индекс для первичного ключа индекс создается автоматически.
Какие накладные расходы от индексов?
- Замедление операций вставки и обновлений. Так как необходимо будет перестраивать индекс при вставке новых значений. Но это должно быть не так страшно, так как профиль нагрузки на реляционную базу данных выглядит следующим образом: 80% запросов это чтение, 20% запросов это запись. Если запросов на запись больше, то возможно реляционная база данных вам не подходит.
- Дополнительные объемы дискового пространства для хранения индекса. Размер индексов на таблицу в половину размера таблицы считается нормальным и оптимальным. Если размер всех индексов таблицы приближается или становится больше, значит что-то идет не так.
- Усложненное технического обслуживание. Индексы пухнут и переодически их нужно пересоздавать. В каких-то СУБД это происходит автоматически. Пересоздание индекса сложный процесс и может повлечь недоступность сервиса.
При создании индекса нужно провести анализ. Иначе можно получить все накладные расходы, и не получить преимущества.
Что нужно для создания индекса?
- Ориентироваться только на продуктовое окружение, так как тестовые окружения не соответствуют реальности.
- Собрать статистику нагрузки на БД от запросов. Чтобы понять какие запросы действительно требуют оптимизации. - ../../dev/database/Плохой SQL запрос. Для этого можно использовать различные инструменты
- ../../dev/database/postgresql/pg_stat_statements
- pgBadger - использовать с осторожностью. Собирает статистику из логов. Но в логи попадают не все запросы.
- Иметь примеры запросов с параметрами. Это необходимо для проверки проведенных оптимизаций.
- Нужно уметь читать статистику распределения данных - ../../dev/database/postgresql/Таблица статистик pg_stats. Это нужно, чтобы понимать как планировщик БД будет строить план выполнения запроса.
- По умолчанию PostgrteSQL использует для сбора статистики только 30k строк из таблицы. Из-за этого статистика может расходиться с реальностью. И нужно уметь собирать более полную статистику вручную. Когда есть подозрения, что в статистике есть существенные промахи.
Далее идет описание типов индексов, которые есть в Postgres, и которые перечислены в моей заметке ../../dev/database/postgresql/Индекс в PostgreSQL#Типы индексов.
Для OLTP нагрузки не стоит использовать параллельное выполнение запроса. Так как это значит, что мы забираем ядро процессора у другого запроса. В OLTP нагрузке каждый запрос должен выполняться на одном процессе так быстро, как только возможно.
Практика

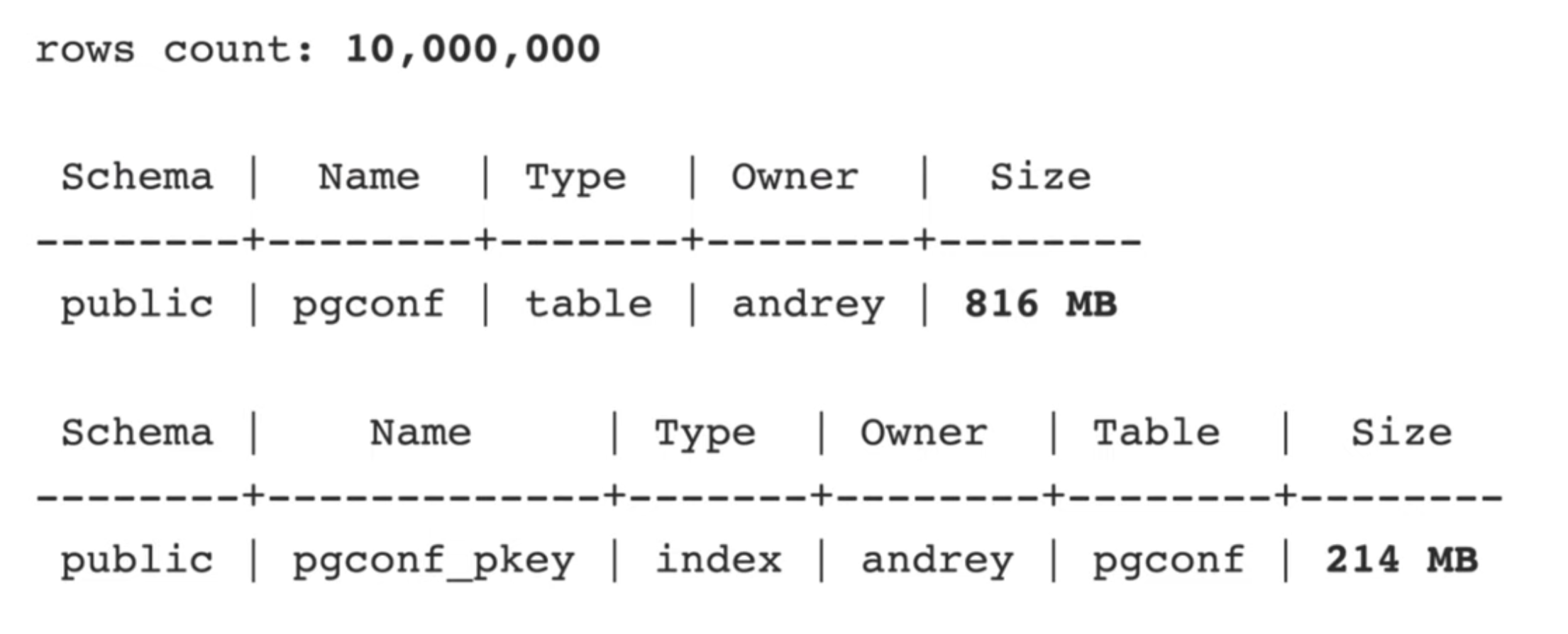
- У таблицы есть первичный (bigint) и внешний ключи.
- Таблица имеет колонки различных типов данных.
- Таблица ссылается сама на себя, но это сделано для удобства доклада. Те же самые выводы распространятся и на связи с другими таблицами.
- Количество кортежей 10_000_000
- Индекс по первичному ключу занял 1/4 (214 Mb) от размера таблицы (816 Mb)
Удаляем строку
Удаляем строку по первичному ключу.
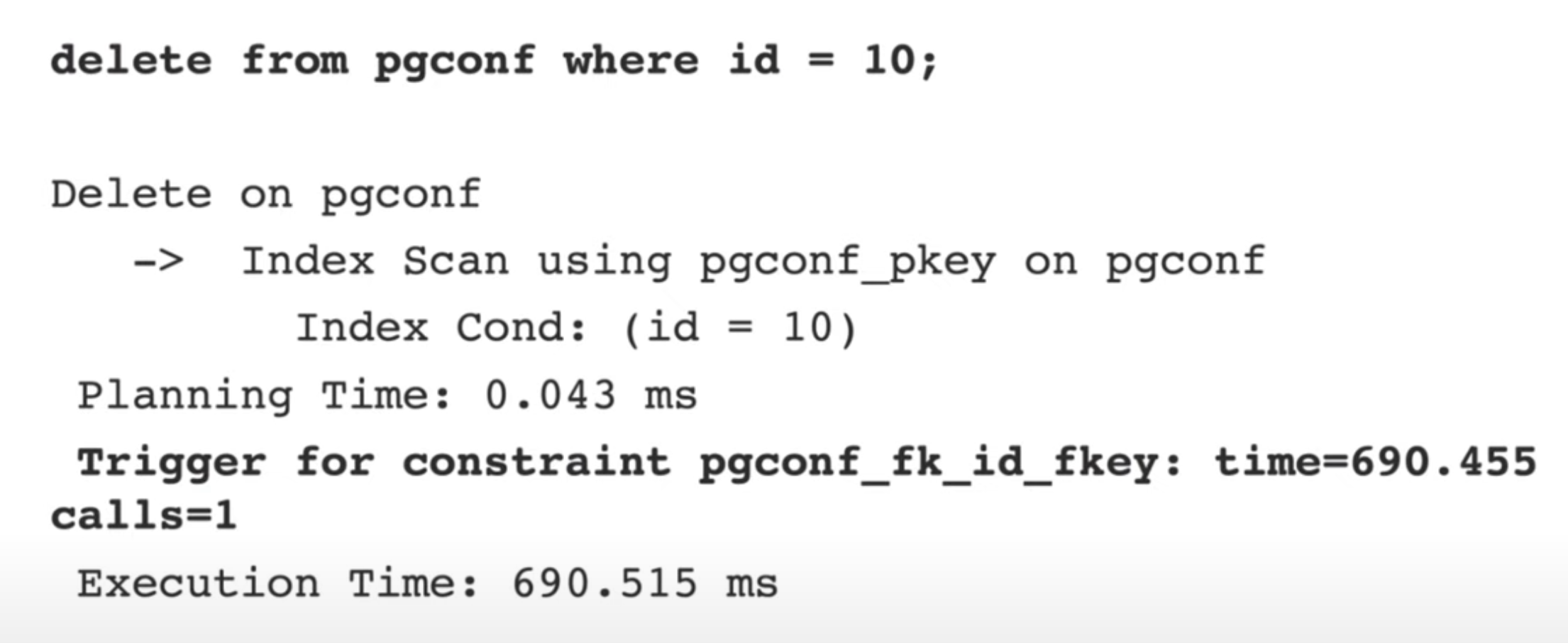 В удалении задействован первичный ключ, поэтому используется поиск по индексу. Но по итогу ==самый долгий этап это проверка внешних связей с таблицей==. По итогу запрос вроде бы быстрый, но он не оптимальный, он потребляет намного больше ресурсов сервера, чем должен.
В удалении задействован первичный ключ, поэтому используется поиск по индексу. Но по итогу ==самый долгий этап это проверка внешних связей с таблицей==. По итогу запрос вроде бы быстрый, но он не оптимальный, он потребляет намного больше ресурсов сервера, чем должен.
Под капотом для поиска внешних связей используется полное сканирование таблицы (Seq Scan). В данном примере специально включено паралеллельное выполнение, но это все равно занимает много времени.

Поэтому важно не забывать ../../dev/database/Индекс для внешнего ключа таблицы БД, чтобы различные проверки БД выполнялись с использованием индекса.
Добавляем индекс на FK и проверяем результат:

Время выполнения было 281 ms, а стало 0.1 ms!
Большинство разработчиков на этом этапе успокоится, но можно ли сделать лучше?
Смотрим статистику
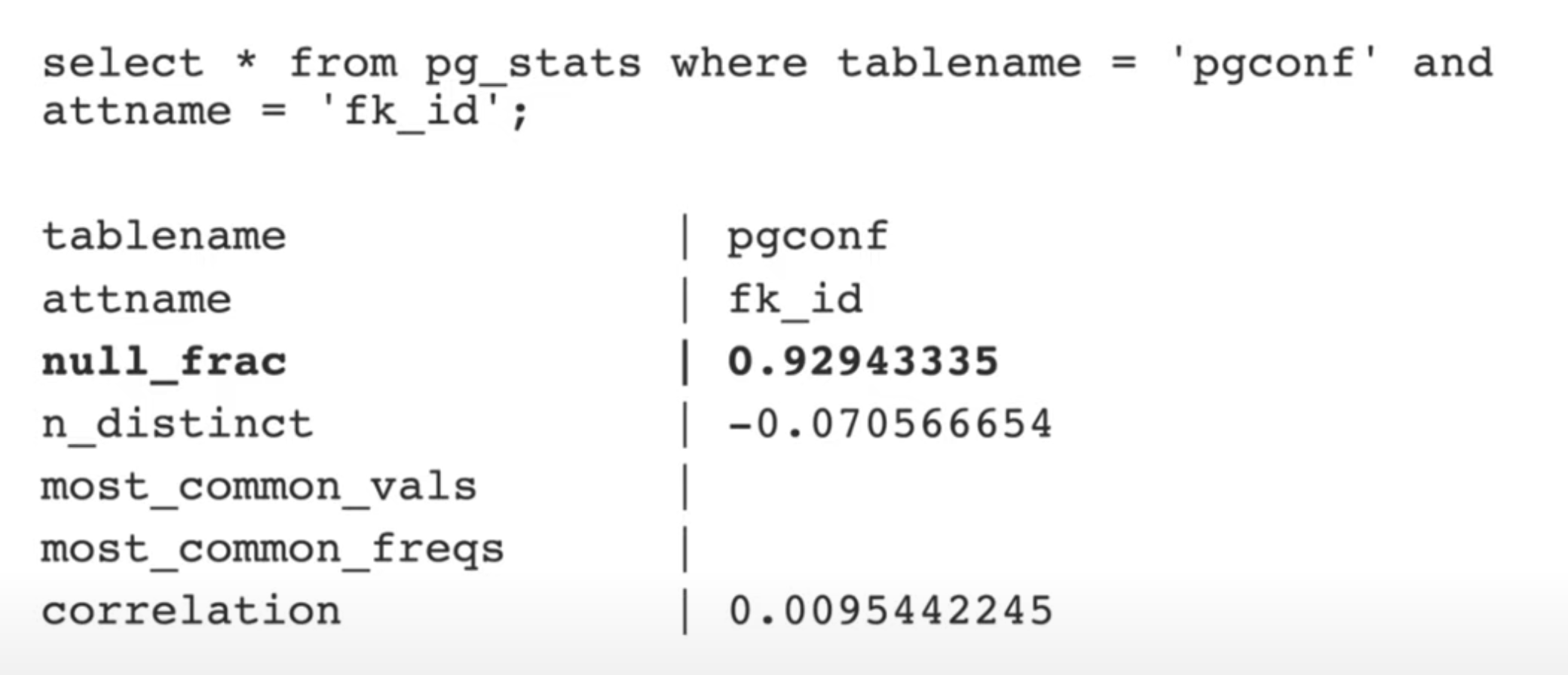
В данном случае у нас 92% значений в колонке это null значения.
При большом значении null_frac нас уже меньше волнуют остальные параметры. Основываясь на этой информации мы можем уменьшить размер индекса. Для этого изменим запрос на создание индекса, добавив where fk_id is not null.
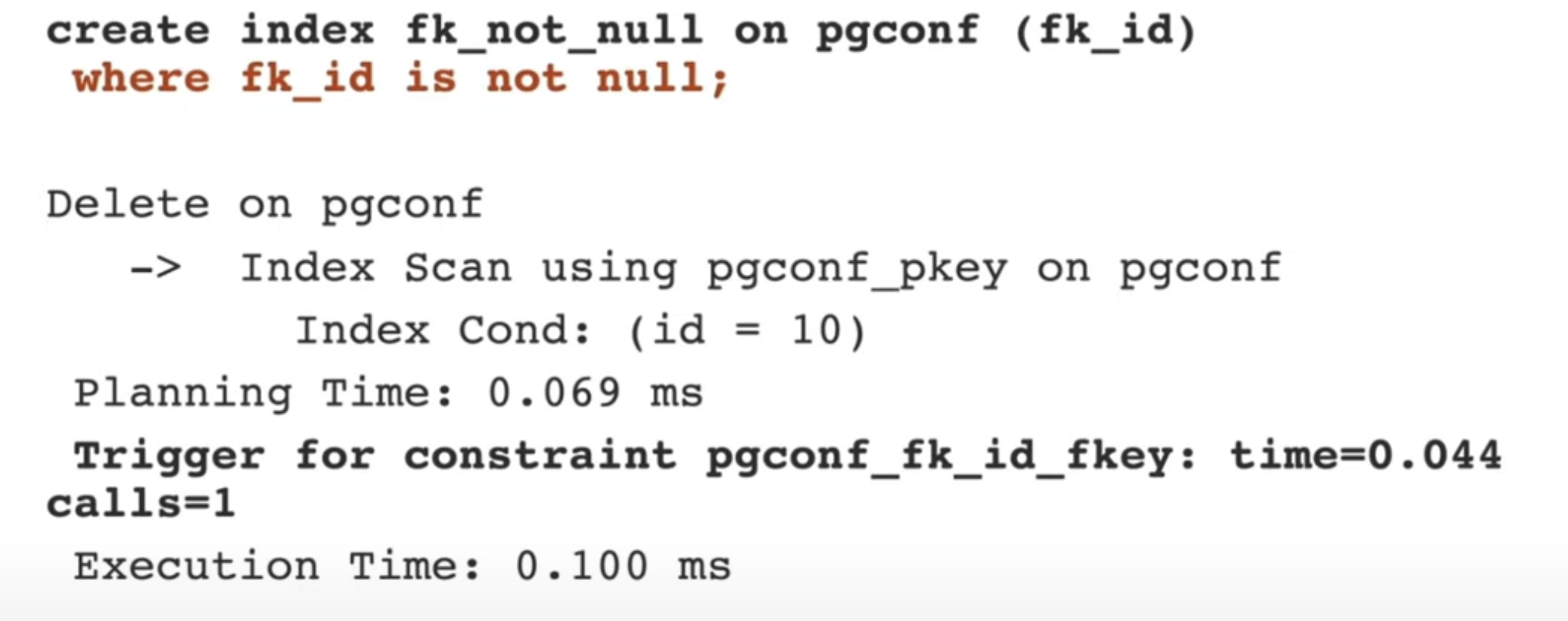
Это не ускорит нам запрос, но таким образом у нас получилось сжать индекс в 14 раз:

Поиск записей по статусу
Возьмем типичную табличку, в которой есть какие-то статусы мы хотим находить данные по этому статусу.


Часто появляется желание сделать индекс по полю статуса:
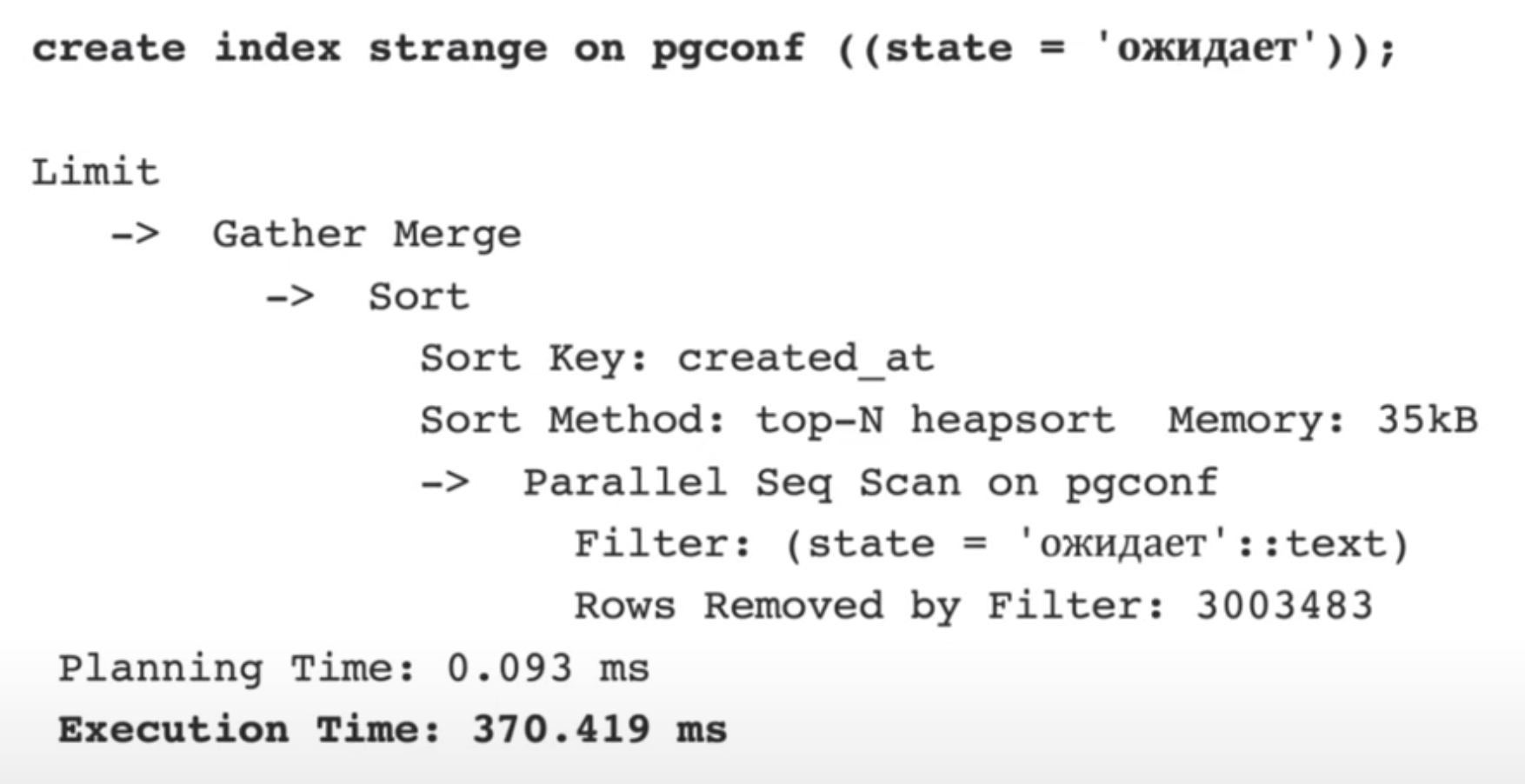
Но по факту мы индексируем поле, которое имеет небольшую селективность. Такой индекс не эффективный.
Хороший вариант в данном случае:

Почти идеальный:
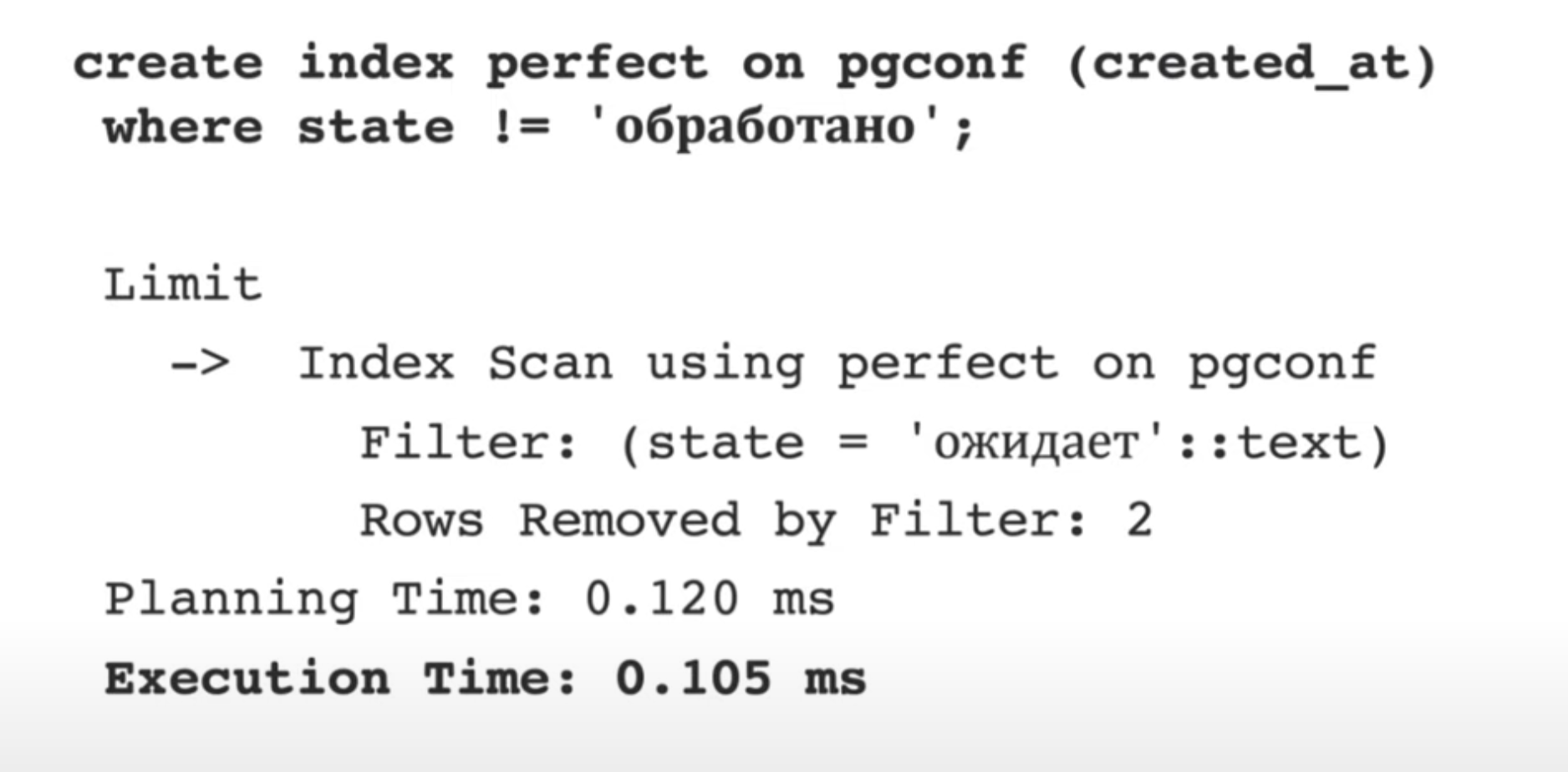

Идеальный. Совмещаем и ../../dev/database/postgresql/Составной индекс в PostgreSQL и ../../dev/database/Частичный индекс
!
Онлайн статистика
Представим, что у вас небольшой продукт и PostgreSQL у вас единственное хранилище данных. И у вас есть задача показывать какую-то аналитику. Обычно для аналитических запросов хорошо использовать колоночные БД. Но так как ресурсов проекта у вас не много и задач на анализ не так много, то позволить себе такое вы не можете.
Можно сделать небольшой шаг в сторону колоночных БД в PostgreSQL за счет индексов.
В данном случае будем показывать сколько фруктов продано. Если использовать в лоб операции coun и sum, то они будут занимать достаточно много времени.
!
Если не используем индексы
!
Лучшее решение здесь это расчитывать заранее агрегирующие результаты за старые данные и обновлять их раз в сутки, а наиболее актуальные (за последние сутки) расчитывать отдельно и приплюсовывать к историческим.
Попробуем придумать индекс. Посмотрим на статистику по полю item. Видим, что больше половины таблицы занимает значение "дыня", значит с дыней придется прочитать половину таблицы.
!
Поэтому первым стоит указать поле created_at, учитывая что оно участвует в запросе, а вторым полем добавить item.
!
Но можно пойти еще дальше и использовать include(amount). Таким образом мы присоединим поле к индексу, оно не будет индексироваться. То есть значение amount будет лежать рядом, не нужно будет доставать значение из таблицы. Также используем where, чтобы отрезать все ненужные колонки.
!
Ответы на вопросы
- Автор в незнакомых базах смотрит
- на соотношение размеров таблицы и индексов.
- на количество чтений индексов
- дальше уже смотрит на то как были созданы индексы