7.6 KiB
| aliases | tags | date | |
|---|---|---|---|
|
2024-10-21 |
Можно создать частичный индекс по условию, который покрывает только записи, удовлетворяющие определенному условию WHERE.
Например, можно исключить из индекса по внешнему ключу (FK) значения NULL:
CREATE INDEX fk_not_null ON pgconf(fk_id)
WHERE fk_id IS NOT NULL;
Частичные индексы позволяют не только уменьшить размер индекса, но и обеспечить более эффективную работу с таблицами, содержащими данные, которые имеют различный статус (например, активные и удаленные записи). Это особенно полезно в случаях, когда необходимо поддерживать уникальность данных и при этом исключить определенные записи из индекса, такие как удаленные или обработанные.
Преимущества:
- Уменьшение размера индекса: Индекс включает только необходимые записи, что уменьшает его общий объём.
- Ускорение запросов: Частичный индекс может улучшить производительность запросов, особенно если он используется для выборки узко определённых данных.
- Оптимизация операций обновления: Поскольку индекс обновляется только для определённых строк, уменьшаются накладные расходы на запись и обновление данных.
Недостатки:
- Ограниченная применимость: Частичные индексы не всегда подходят, особенно для данных с высокой селективностью, где обычные индексы будут более эффективны.
- Сложность настройки: Необходимо тщательно выбирать условия
WHERE, чтобы получить максимальную пользу от частичного индекса. Неправильный выбор условий может привести к ухудшению производительности.
Когда использовать частичные индексы:
- Когда необходимо уменьшить размер индекса за счёт исключения ненужных записей, что позволяет сэкономить место на диске и ускорить операции поиска.
- Когда таблица содержит большое количество записей с одинаковыми значениями (низкая Селективность колонки), и вам нужно индексировать только те записи, которые имеют уникальные или более специфичные значения.
- В ситуациях, когда индекс нужен для работы с данными, которые соответствуют определённому условию, например, только "необработанные" записи.
Применение частичных индексов
Таблицы с колонкой статуса
Часто в приложениях есть таблицы, которые содержат колонку статуса (state). Обычно статус разделяет записи на "обработанные" и "необработанные". Индекс нам часто нужен именно по необработанным данным. Создавая частичный индекс только по необработанным данным, мы можем ускорить выполнение запроса и уменьшить размер индекса.
Возьмем типичную табличку, в которой есть какие-то статусы мы хотим находить данные по этому статусу.


Часто появляется желание сделать индекс по полю статуса:
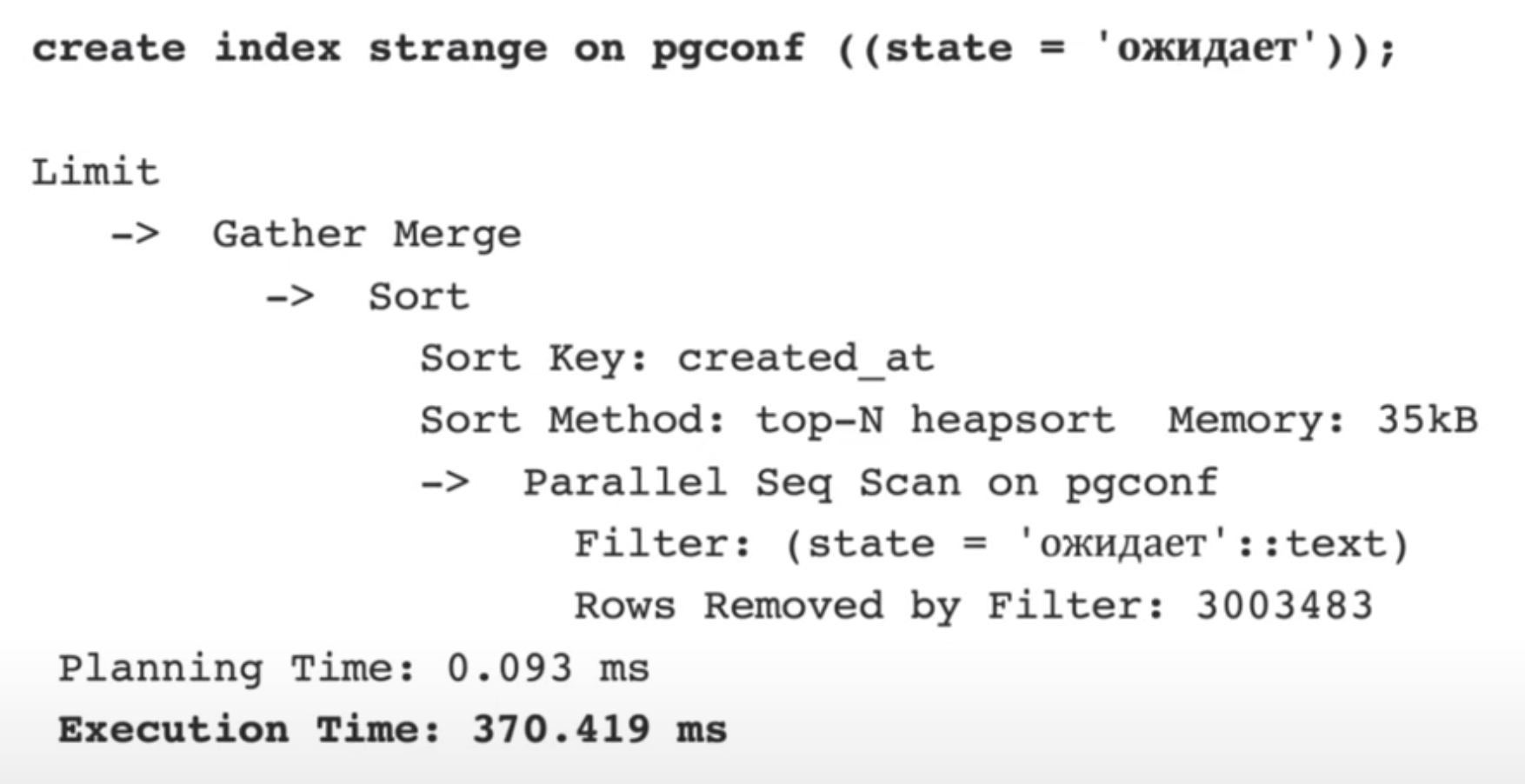
Но по факту мы индексируем поле, которое имеет небольшую селективность. Такой индекс не эффективный.
Хороший вариант в данном случае:

Почти идеальный:
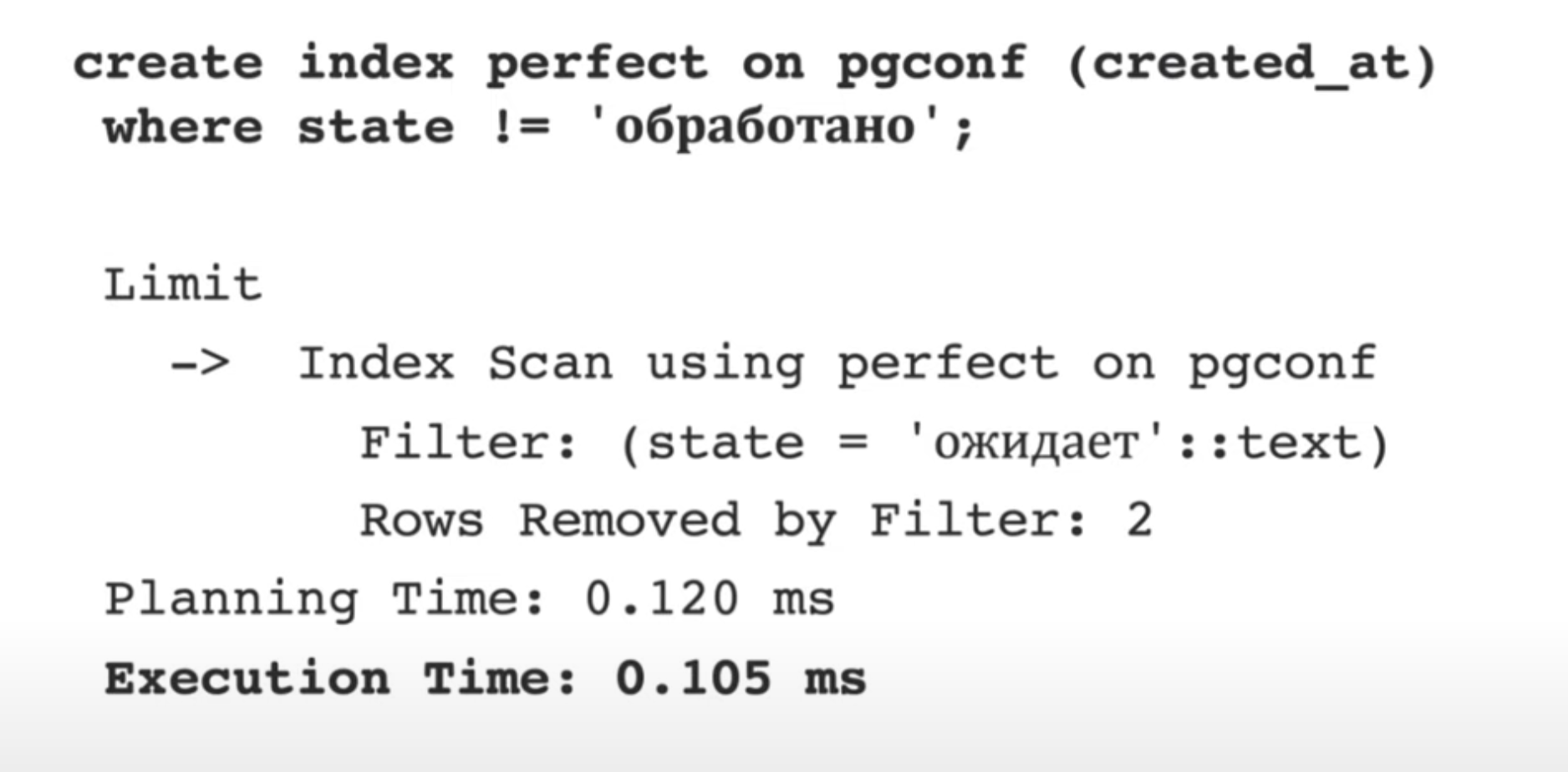

Идеальный. Совмещаем и postgresql/Составной индекс в PostgreSQL и частичный.
!
Для мягкого удаления
Представьте, что вам нужно поддерживать уникальность данных, например, адресов электронной почты в таблице базы данных. Однако в таблице есть строки, ../Tombstone с помощью поля deleted_at, и они также остаются в базе данных. В такой ситуации создание уникального индекса на поле с электронной почтой становится невозможным из-за дублирующихся значений. Частичный индекс решает эту проблему, позволяя включать в индекс только записи, которые не помечены как удаленные.
В PostgreSQL добавление уникального индекса для активных пользователей выглядит так:
CREATE UNIQUE INDEX users_email_uniq ON users (
email
) WHERE deleted_at IS NULL;
В этом случае строки, у которых deleted_at не задан, включаются в индекс, а остальные игнорируются, что делает индекс более компактным и эффективным.
Мета информация
Область:: ../../meta/zero/00 PostgreSQL Родитель:: Индекс в PostgreSQL, Оптимизация SQL запросов в PostgreSQL Источник:: Создана:: 2024-10-21 Автор::