17 KiB
| aliases | tags | date | zero-link | parents | linked | ||
|---|---|---|---|---|---|---|---|
|
|
2023-11-12 |
UUID (Universal Unique IDentifier) — это 128-битный идентификатор, представленный в виде строки. Однако для пользовательских данных доступно только 122 бита, так как 6 бит зарезервировано:
- 4 бита используются для указания версии UUID;
- 2 бита определяют вариант UUID.

Заполнение 122 бит зависит от версии UUID:
- Специальные UUID:
- Nil UUID — все биты равны 0.
- Max UUID — все биты равны 1 (или “f” в шестнадцатеричной записи).
- Стандартные версии UUID (по спецификации RFC 4122) — всего 5 версий.
- Новые версии — три дополнительных варианта, не описанных в RFC 4122.
UUID V1

UUID версии 1 использует текущее время по григорианскому календарю и имеет следующие особенности:
- Время записывается в обратном порядке, что делает невозможной сортировку UUID по времени создания.
- Включает случайную компоненту для увеличения уникальности.
- Node ID привязан к сетевому оборудованию (обычно к MAC-адресу). Это значение рекомендуется подменять на псевдослучайное для повышения конфиденциальности.
Недостатки:
- Не подходит для сортировки по времени.
Преимущества:
- Быстрая вставка в базу данных, независимо от размера данных.
- UUID сложно перебрать за счет высокой энтропии.
- Возможность извлечь метку времени из идентификатора.
UUID V3

UUID версии 3 (V3) — это идентификатор, основанный на алгоритме хеширования cryptography/MD5. В отличие от UUID версии 1, который использует текущее время, UUID V3 генерируется на основе имени (строки) и пространства имен (namespace). Основная идея заключается в том, что при использовании одинаковых имени и пространства имен результатом всегда будет один и тот же UUID.
Пример использования: Когда нужно сгенерировать уникальный идентификатор для имени домена в сети, применяется UUID V3 с пространством имен DNS и строкой, содержащей доменное имя. Например:
UUID(DNS, "example.com") → 5df41881-3aed-3515-88a7-2f4a814cf09e
Преимущества:
- Детерминированность: один и тот же вход (имя + пространство имен) всегда генерирует одинаковый UUID, что удобно, если требуется уникальный идентификатор для конкретного объекта, который может быть повторно создан.
Недостатки:
- Зависимость от MD5: Алгоритм cryptography/MD5 считается криптографически уязвимым, что делает UUID V3 неподходящим для использования в приложениях, требующих высокой безопасности.
- Не случайный: В отличие от UUID версии 1 или 4, UUID V3 предсказуем, так как основывается на статическом входе.
UUID V4

UUID версии 4 (V4) — это случайный идентификатор, где большинство битов генерируются случайным образом. Вся структура UUID V4 почти полностью случайна, за исключением 6 бит, зарезервированных для указания версии и варианта.
Преимущества:
- Сложность перебора: Из-за случайной природы UUID V4 крайне сложно предугадать следующий идентификатор или перебрать все возможные значения. Всего существует 2^{122} возможных вариантов UUID V4, что делает их практически уникальными в реальных условиях.
- Простота генерации: Процесс создания UUID V4 не требует внешних данных (время, имя или пространство имен), что делает его проще в реализации и использовании.
- Конфиденциальность: Поскольку в UUID V4 нет привязки к времени или аппаратному обеспечению (в отличие от V1), он не раскрывает никакой дополнительной информации, такой как метка времени или MAC-адрес устройства.
Недостатки:
- Не сортируемый: UUID V4 нельзя отсортировать по времени или другим критериям, так как он полностью основан на случайных данных.
- Замедленная вставка в БД: В больших базах данных, по мере увеличения количества записей, время вставки новых записей с UUID V4 может расти. Это связано с тем, что случайные значения распределяются неравномерно, что может вызывать фрагментацию database/Индекс в БД, особенно при использовании кластеризованных индексов.
- Не содержит полезной информации: В отличие от UUID версий 1 и 3, UUID V4 не хранит никаких дополнительных данных (например, метку времени или привязку к конкретному объекту).
UUID V5

UUID версии 5 (V5) очень похож на UUID версии 3 (V3), с той лишь разницей, что вместо cryptography/Хеш-функция cryptography/MD5 используется более современная и безопасная cryptography/Хеш-функция SHA-1. Как и в случае с V3, UUID V5 генерируется на основе входных данных — имени и пространства имен (namespace).
Преимущества:
- Детерминированность: Как и UUID V3, версия 5 всегда генерирует один и тот же UUID для одного и того же сочетания имени и пространства имен.
- Современная хеш-функция: В отличие от устаревшего и криптографически слабого cryptography/MD5, SHA-1 обеспечивает более высокую безопасность, хотя и не является идеальной для криптографических приложений в наше время.
- Уникальность в пределах пространства имен: Гарантирует уникальность идентификаторов при использовании различных пространств имен.
Недостатки:
- Время вставки в базу данных: В больших базах данных с увеличением количества записей может увеличиваться время вставки, особенно если UUID используется как индекс. Это связано с неравномерностью распределения случайных значений.
- Не сортируемый: Как и UUID V4, идентификаторы версии 5 не могут быть отсортированы по времени или другим логическим критериям, поскольку они зависят от хеширования входных данных.
- Не хранит полезной информации: UUID V5 не содержит дополнительных данных, таких как метка времени, информация о хосте или устройстве.
UUID V6

UUID версии 6 (V6) был разработан для устранения одного из ключевых недостатков UUID версии 1 (V1) — невозможности сортировки. UUID V6 сохраняет идею использования времени для генерации идентификатора, но изменяет порядок записи временной метки, что позволяет идентификаторам быть сортируемыми по времени.
Преимущества:
- Сортируемость: Главное отличие UUID V6 от V1 — это возможность сортировки идентификаторов по времени их создания. UUID V6 можно отсортировать по времени.
- Метка времени: UUID V6 сохраняет возможность извлечения метки времени из идентификатора, что полезно для некоторых приложений, где важно отслеживать время создания записи.
- Конфиденциальность: Как и в V1, UUID V6 может включать привязку к оборудованию (например, MAC-адрес), но рекомендуется использовать псевдослучайные данные для повышения конфиденциальности.
Недостатки:
- Сложность в использовании с кластеризованными индексами: Хотя UUID V6 улучшает сортировку, время вставки в базу данных может увеличиваться при большом количестве записей, особенно если используется кластеризованный индекс, который требует поддержания порядка.
- Не случайный: В отличие от UUID V4, версия 6 не является полностью случайной, что может быть недостатком в сценариях, где важна непредсказуемость.
UUID V7

UUID версии 7 (V7) представляет собой новую версию UUID, которая использует Unix-время вместо григорианского, применяемого в UUID версии 1 (V1). Такой подход делает UUID V7 более компактным и эффективным для хранения временных меток, поскольку Unix-время занимает меньше места по сравнению с григорианским временем.
Преимущества:
- Сортируемость: UUID V7 сохраняет временные метки в формате Unix, что делает его естественно сортируемым по времени создания. Это полезно для реляционных баз данных, где важен порядок записей.
- Константное время вставки: Поскольку UUID V7 монотонно увеличивается со временем и включает случайные данные, вставка в базу данных происходит с постоянным временем.
- Метка времени: UUID V7 сохраняет метку времени, что позволяет извлечь момент создания идентификатора.
- Сложность перебора: UUID V7 сохраняет высокий уровень уникальности за счет случайных битов, что делает его труднопредсказуемым и сложным для перебора.
Недостатки:
- Меньшая случайность в начальной части: Поскольку первые биты связаны с временной меткой, это снижает уровень случайности в первой части UUID. Однако это компенсируется случайной частью идентификатора.
UUID V7 может иметь несколько типов генерации, в зависимости от требуемого уровня случайности и последовательности.
- Тип 1 (по умолчанию):
UuidCreator.getTimeOrderedEpoch();- Плюсы: Сортируемый, достаточно быстрый, подходит для большинства приложений, где важна как уникальность, так и последовательность.
- Минусы: Более низкий уровень случайности по сравнению с другими типами.
- Тип 2 (плюс 1):
UuidCreator.getTimeOrderedEpochPlus1();- Обеспечивает более высокую уникальность и последовательность за счет монотонного увеличения.
- Плюсы: Подходит для приложений, требующих строгого соблюдения порядка идентификаторов.
- Минусы: Менее случаен, чем Тип 3.
- Производительность: Генерируется в 20 раз быстрее, чем
UUID.randomUUID().
- Тип 3 (плюс n):
UuidCreator.getTimeOrderedEpochPlusN();- Особенности: Максимальная уникальность за счет случайного увеличения.`
- Плюсы: Подходит для сценариев, требующих высокой уникальности без строгих требований к последовательности.
- Минусы: Меньшая предсказуемость и последовательность по сравнению с Типами 1 и 2.
- Производительность: Генерируется в два раза быстрее, чем
UUID.randomUUID().
Производительность
Генерируем по 200000 идентификаторов в цикле, после чего вставляем эти данные.
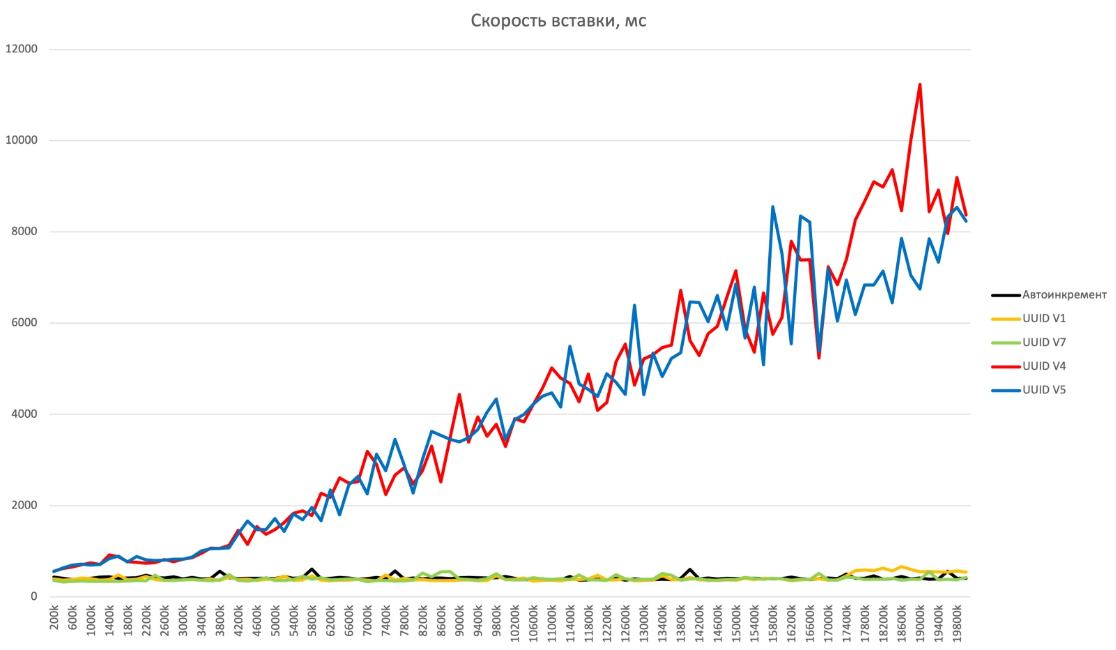
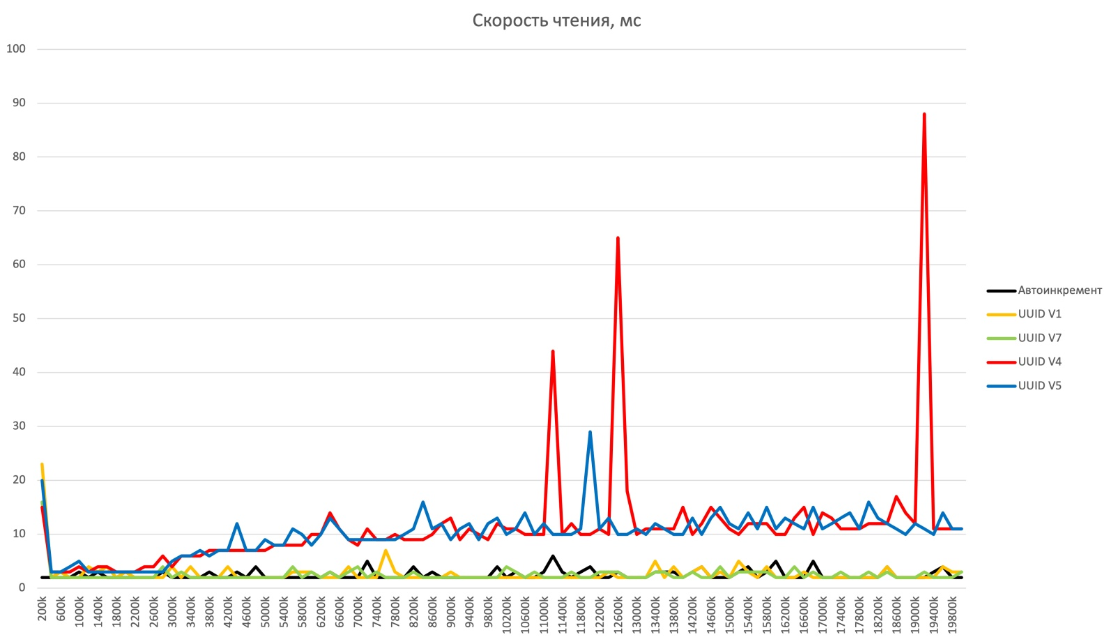
Массовое чтение, через IN

Мета информация
Область:: ../meta/zero/00 Разработка Родитель:: Источник:: Автор:: Создана::
Дополнительные материалы
- ID-баттл: UUID vs автоинкремент / Валентин Удальцов - YouTube
- Библиотека для генерации UUID в Java. Все версии
- ../../../_inbox/Автоинкремент