13 KiB
| aliases | tags | date | zero-link | parents | linked | link | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
|
|
Тезисы
- На slave можно реализовать другую схему БД, построить другие индексы.
- Можно использовать libslave, чтобы "притвориться" репликой.
- Мастер многопоточен, а слейв - нет. Вроде исправлено в новых версиях SQL.
- В 5.6 версии можно реплицировать параллельно несколько БД
- В 5.7 версии можно реплицировать параллельно одни и те же таблицы
- Обязательно убедиться, что работают GUID идентификация транзакций.
- Репликация сильно зависит от версии MySql
- Всегда логическая репликация, модель master-slave, pull распространение
- 4.1 = асинхронная, SBR, logposs
- 5.1 = +RBR, +mixed. Дефолт mixed
- 5.6 = +semisync, +mtslave (per-db), +slavedelay, +GTID
- 5.7 = + mtslave, +master-master (plugin), +default-RBR (image=full?!), groupcommit
Схема работы репликации
Физический слой хранилища должен писать журнал для работы транзакций (Write-Ahead Log). По идее, его можно было бы использовать для репликации, как в PostgreSQL, но логический слой ничего не знает про физический и не может использовать тот же журнал. Поэтому при включении репликации на логическом уровне master начинает вести свой журнал, называемый Binary Log.
Механизм работы следующий:
- Запись изменений в бинарный лог: Все изменения данных записываются в бинарный лог (Binary Log) на мастере. Бинарный лог хранит последовательность всех транзакций, которые изменяют данные.
- Передача бинарного лога на реплики: Мастер передает бинарный лог на реплики. Для этого используются потоки binlog dump на мастере и I/O потоки на репликах. В отличие от PostgreSQL, используется pull модель распространения, то есть реплики сами забирают изменения с master.
- Применение изменений на репликах: Реплики считывают бинарный лог и применяют изменения к своим копиям данных, поддерживая синхронизацию с мастером.

Binary Log в MySQL может записывать данные в разных форматах, в зависимости от настроек журнала. Рассмотрим основные из них:
Процесс записи данных операции в MySQL
- INSERT INTO test VALUES (123, 'hello')
- Записываем в таблицу на мастере mysqld
- Записываем в binary log на мастере
- Записываем в relay log на слейве
- таблица на слейве mysqld
Рабочие потоки (MySQL Replication Threads):
- binlog dump thread. Сохраняет лог транзакций на master
- slave I/O thread. Спуливает изменения на slave с master
- slave SQL thread. Применяет изменения на slave
MySQL не решает из коробки проблемы кластеризации. Из коробки нет переключений со slave на master если мастер сдох, распределения нагрузки и так далее. Можно решить дополнительным софтом:
- MHA (MySQL Master HA)
- MySQL Failover (Oracle)
- Orchestrator
Фильтрация репликации
Можно реплицировать данные частично, но это стоит использовать осторожно. Например, это не работает с Групповая репликация
Опции:
- replicate_do_db
- replicate_ignore_db
- replicate_do_table
MySQL - CHANGE REPLICATION FILTER Statement

- В InnoDB, заметьте, т.е. у нас архитектура разделяет репликацию выше, а storage engine ниже. Но storage engine, для того, чтобы репликация работала, должен, грубо говоря, замедлять insert'ы в таблицу.
- Другая проблема состоит в том, что мастер выполняет запросы параллельно, т.е. одновременно, а слэйв их может применять последовательно. Возникает вопрос – а почему слэйв не может применять их параллельно? На самом деле, с этим все непросто. Есть теорема о сериализации транзакций, которая рассказывает, когда мы можем выполнять запросы параллельно, а когда последовательно. Это отдельная сложная тема, разберитесь в ней, если вам интересно и нужно, например, почитав по ссылке – http://plumqqz.livejournal.com/387380.html.
- В MySQL репликация упирается в процессор. Это прекрасная картинка – большой, мощный сервер, 12 ядер. Работает одно ядро, заодно занято репликацией. Из-за этого реплика задыхается. Это очень грустно.
Для того чтобы выполнять запросы параллельно существует группировка запросов. В InnoDB есть специальная опция, которая управляет тем, как именно мы группируем транзакции, как именно мы их пишем на диск. Проблема в том, что мы можем их сгруппировать на уровне InnoDB, а уровнем выше – на уровне репликации – этой функциональности не было. В 2010 г. Кристиан Нельсен из MariaDB реализовал такую фичу, которая называется Group Binary Log Commit. Получается, мы журнал повторяем на двух уровнях – Storage Engine и репликация, и нам нужно таскать фичи из одного уровня на другой. Это сложный механизм. Более того, нам нужно одновременно консистентно писать сразу в два журнала – two-phase-commit. Это еще хуже.
На следующей картинке мы видим два графика:
 Синий график демонстрирует то, как масштабируется InnoDB, когда мы ему добавляем треды. Накидываем треды – число транзакций, которые он обрабатывает, возрастает. Красная линия показывает ситуацию, когда включена репликация. Мы включаем репликацию и теряем масштабируемость. Потому что лог в Binary Log пишется синхронно, и Group Binary Log Commit это решает.
Синий график демонстрирует то, как масштабируется InnoDB, когда мы ему добавляем треды. Накидываем треды – число транзакций, которые он обрабатывает, возрастает. Красная линия показывает ситуацию, когда включена репликация. Мы включаем репликацию и теряем масштабируемость. Потому что лог в Binary Log пишется синхронно, и Group Binary Log Commit это решает.
Грустно, что приходится так делать из-за разделения – Storage Engine внизу, репликация наверху. С этим все плохо. В MySQL 5.6 и 5.7 эта проблема решена – есть Group Binary Log Commit, и мастер теперь не отстает. Теперь это пытаются использовать для параллелизма репликации, чтобы на слэйве запросы из одной группы запустить параллельно. Тут я написал, что из этого нужно крутить:

Параллельная репликация
Сценарий (Estimating potential for MySQL 5.7 parallel replication):
- 1 мастер, 3 слейва
- первый реплицирует в 1 поток
- второй в 20 потоков
- третий в 100 потоков
- вставка в 25 различных таблиц внутри одной базы в 100 потоков
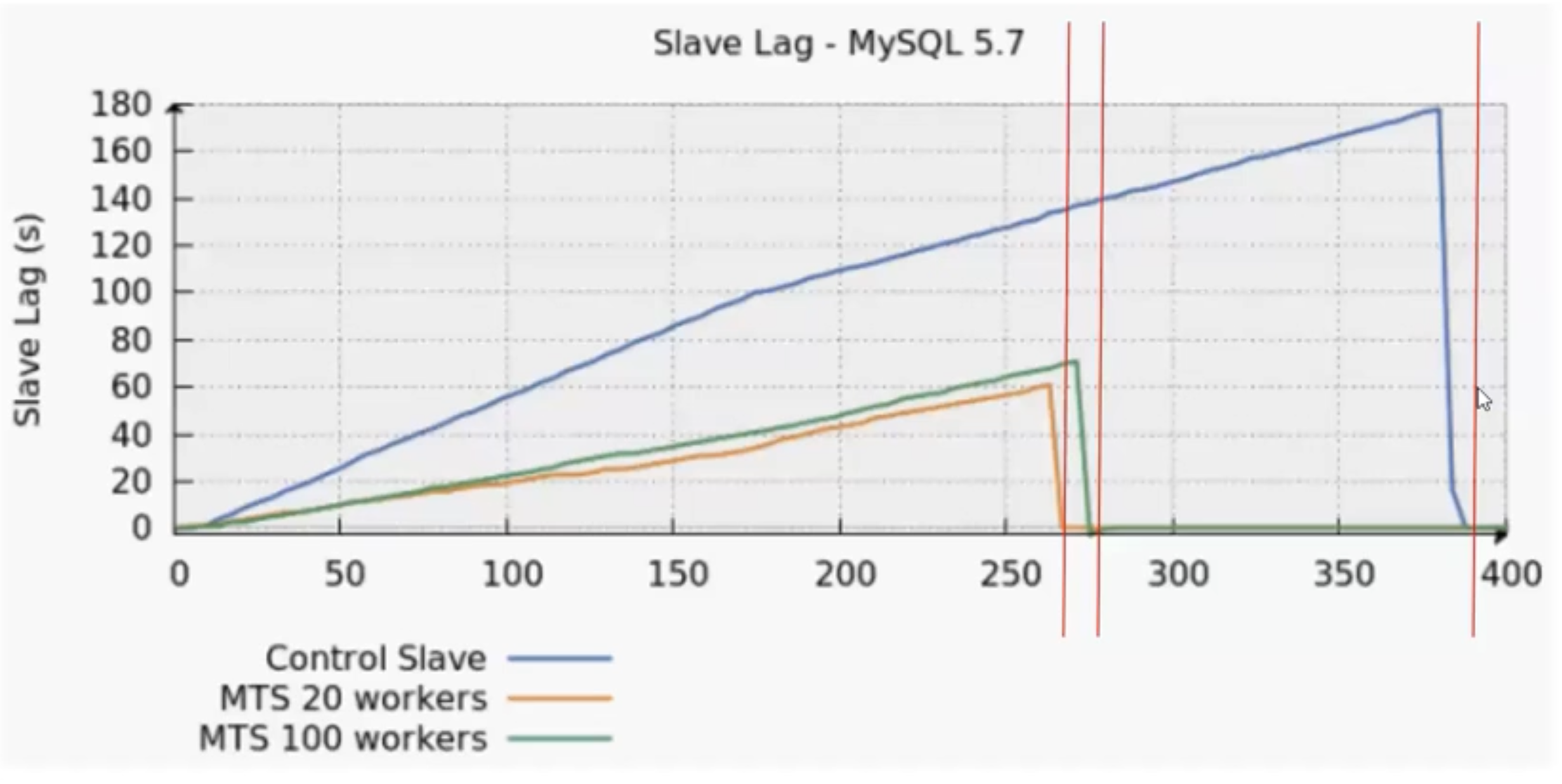
Полезные опции:
- sysvar_replica_parallel_workers - количество потоков
- sysvar_replica_parallel_type
- DATABASE - транзакции применяются параллельно, если они обновляют разные БД
- LOGICAL_CLOCK - транзакции применяются параллельно на реплике на основе timestamp
Отставание реплики
Диагностировать причину отставания реплики тяжело. Есть средство диагностики в MySQL, называется log медленных запросов. Вы можете его открыть, найти топ самых тяжелых запросов и исправить их. Но с репликацией это не работает. Нужно проводить статистический анализ – считать статистику – какие таблицы стали чаще использоваться. Вручную это сделать очень тяжело.
В MySQL 5.6 / 5.7 появилась SLAVE PERFORMANCE SCHEMA, на базе которой такую диагностику провести проще. Мы обычно открываем лог коммитов в puppet и смотрим, что же мы выкатили в то время, когда репликация начала отставать. Иногда даже это не помогает, приходится ходить по всем разработчикам и спрашивать, что они сделали, они ли сломали репликацию. Это грустно, но с этим приходится жить.
Мета информация
Область:: ../../../meta/zero/00 MySQL Родитель:: ../../architecture/highload/Репликация БД Источник:: Автор:: Создана:: 2024-05-28
Дополнительные материалы
- Как устроена MySQL-репликация / Андрей Аксенов (Sphinx) - YouTube
- Асинхронная репликация без цензуры / HighLoad